Content
DevOps

How to Ensure Cloud Scalability in 2023

As the common volumes of load on computing systems increasingly grow, they adapt and become more complex in terms of basic architecture. New software tools and integration for performance optimization are added, server capacities are expanded, etc.

All these system optimization processes are defined by a single notion - scaling - one of the key specializations of DevOps experts. What is scalability and, more importantly, how to ensure it in the case of your particular business with most operating capacities concentrated in the cloud? Let’s dive into the subject.

Image source: Static.bluepiit
What Is Scalability?
What’s the ultimate definition of scalability? It is, basically, an ability to increase the system performance in the most rational way possible. In practice, this is usually achieved by adding up computing resources, both hardware and/or software ones. Rewritten existing code, however, is quite a drastic solution in most cases, so in 9 out of 10 cases companies stop at multiplying the number of servers or boosting capabilities of the existing server system.
Notice that the need for scaling not only appears when the overall system performance becomes laggy and insufficient. The existing and operating architecture may perform just fine and yet lags may still hinder processes due to the rapid growth of user traffic.
If you wish to check how efficiently your network protocols and web server resources at hand perform, you can use any available load tester utility (like siege, for instance) that will emulate an artificial user influx to your server with tons of requests. You’ll just have to track two key parameters: n - defines a total number of requests and c - indicates the number of simultaneous requests.
As a result, you get an RPS (requests per second) reading which shows how many requests your server system is capable of handling at the moment. This is the reflection of the maximum number of users that, if they try to interact with your server all at once, will probably crash your system down. This testing routine ultimately shows you what to expect and how important it is to establish prone to scalability architecture.
On the other hand, though, think about it for a second. Perhaps, it’ll be more affordable to customize some server configurations and optimize cashing procedures in your particular case. That way, you can safely postpone scaling until better times.
Why do we need to pay special attention to scalability?
Once a business starts developing, it must be as flexible and resourceful as possible. Startups need to be able to quickly adapt to changing trends and market conditions in order to be popular and competitive. When your app is scalable, it will accelerate your growth, improve user experience, and reach a larger audience. At its core, scalability allows you to better manage your application and adapt to new requirements. When building a growth strategy for your business, building a scalable application should be one of the first priorities.
Types of Scaling
The major and most common types of scaling procedures include:
Vertical Scalability - scaling up
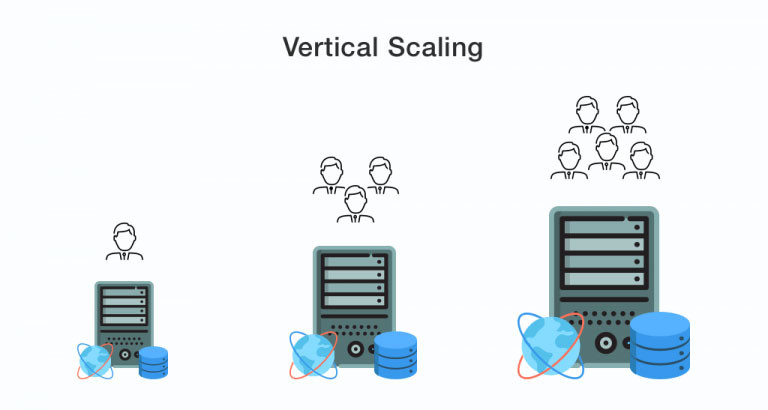
Image source: Dzone
Vertical scaling is when overall business powers are grown by boosting the performance of internal server resources - CPUs, memory, drives, and network capacities. The server in its basic form remains unchanged.
Horizontal Scaling - scaling out
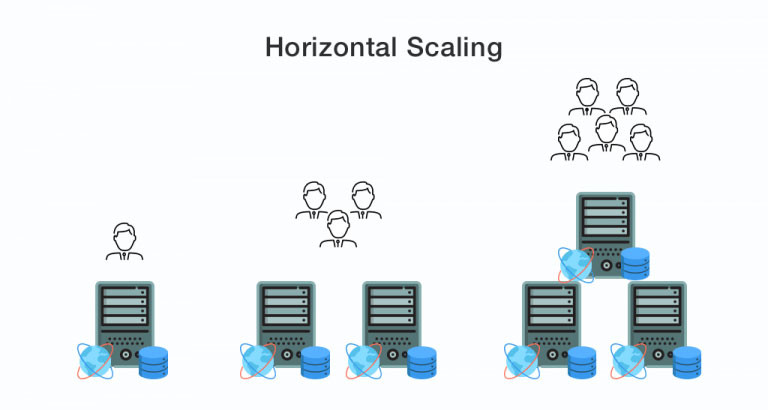
Image source: Dzone
There’s a real stand taking place in the field - scale up vs scale out. What’s better?
In particular, as the digital load and traffic grow ever increasingly, sooner or later vertical scaling faces limits in the form of technical specifications of servers. That’s where horizontal scaling comes into play. The basic meaning of the term defines that the computing powers are increased by adding identical nodes on top of the existing ones. Horizontal scaling is most frequently settled when there is an adjusted server infrastructure in place (particular case - data centers) as well as the settled scheme of interaction between the servers.
Diagonal Scaling
This is a relatively new term that John Allspaw came up with - an author and co-founder of Adaptive Capacity Labs. Thus, diagonal scaling combines the best of two worlds and defines vertical scaling of the horizontally scaled nodes that are already implemented in the existing server infrastructure.
How to Ensure Maximum Scalability
Now, for some practical tips to help you conduct a procedure of cloud computing scalability most properly, with minimum expenses.
Conduct load balancing
Load balancing implies a set of efforts on distributing computing network processes among several hardware-software resources (drives, CPUs, or separate servers) that are concentrated in one socket or cluster. The main goal here is to optimize computing capacities’ expenditures, boost network output, reduce time expenses during the processing of network requests, as well as lower the chances of a certain server replying to DDoS at some wonderful moment.
Moreover, the distribution of load between several nodes (instead of utterly exploiting a single node) boosts the accessibility of services your company provides. In particular, with some excessive server numbers under one’s sleeve, even if some working unit fails, you have an automatic replacement ready.
The procedure of balancing is implemented with the help of a whole set of algorithms and methods each corresponding to the following OSI model layers: Network, Transport, and Application. In practical realization, these require employing several physical servers along with specialized software similar to the Nginx web server.
Turn to auto web services scalability
Auto-scaling is a special approach to dynamic scaling in the context of cloud services (i.e., the scaling that implies customizing computing powers according to the network load volume). Particularly, users of services that include auto-scaling procedures (the most renowned of which are Amazon Web Service, Google Cloud Platform, and Microsoft Azure) are provided with additional virtual machines if need be (which can be automatically excluded from the cluster or container as the traffic and intensity of requests settle down).
Due to such an approach, companies get enhanced accessibility, fail-operational capability, as well as ultimate budget-saving opportunities. With such services, you employ just as much server power as you need at the moment. This is quite a winning option as opposed to physical scaling when you have to purchase and further maintain expensive hardware.
Notice that automatic cloud scalability always goes hand in hand with load balancing solutions.
Microservices containers, clusterization
You can employ resource-efficient, performance-boosting procedures that wrap services into containers, then gather these containers into clusters. The clusterization is followed by defining scripts that either add lacking resources (instances) if need be or minimize the dedication of resources to avoid the excess.
Implement caching
During horizontal scaling, simple memory caching cannot be implemented for several nodes at once, so it’s needed to be optimized. In particular, such storage as Memcached or Redis can be used for the combined distribution of cache data between application iterations. These tools work according to different algorithms so that the caching data is reduced in amount. Cache storages are also well-protected from replication and data storage errors.
Using cache storage, it’s crucial to prevent the situation when different app iterations request uncached data simultaneously. For that, one has to update the caching data outside of your app’s performance flow and use them directly within the app.
As such, with a proper approach, caching can help your systems get a cloud scaling ability to handle intensive loads and achieve an optimal output.
Employ CDN services
CDN is a network of physically remote computers that transfer content to service users. In other words, it is a distributed storage and employment of cache. Usually, turning to CDN is most relevant when a web service, website, or full-blown application targets a user audience that is distributed throughout the territory of multiple countries. CDN pricing depends directly on the volumes of traffic that go through the service.
Alternatively, CDN can be an unprofitable solution if your TA, despite its wide territorial distribution, has localizations with the concentration of certain users. I.e., suppose that about 60% of your TA is based in the USA, 30% in London, and the rest 10% are scattered all over the planet. In such a case, using CDN will be a rational decision only for the latter 10% (whereas other locations will require new servers to be installed).
How Do We Handle Scaling Issues?
Currently, among our brightest examples of scaling conducted by in-house experts include building a high scalability architecture for such public cloud storage as AWS, Microsoft Azure, Google Cloud, and Digital Ocean. We employ automated environment deployment scripts with the help of Terraform - a next-generation system for the creation, management, and configuration of cloud infrastructure. We base our server clusters on the auto-scaling software Kubernetes and the assisting containerization technology Docker.
Conclusion

Image source: CDN.Lynda
By harnessing the scalability in the cloud computing environment through the above and other methods, you can grow quicker and easier, and stay agile all the way. If you strive to adopt only the utterly conscientious approach to scaling, you should definitely turn to experts. Let us find you the DevOps specialists that would provide the most optimal server infrastructure for your particular business, which will be adapted to handle loads of any intensity.



Let professionals meet your challenge
Our certified specialists will find the most optimal solution for your business.


